






Human genetics has advanced enormously over the last twenty years, but it is still being held back by diversity issues. Solving these problems is essential if we are ever to reach true precision medicine for all.
Since the completion of the human genome project 20 years ago, the field has changed beyond all recognition. It is now possible to sequence a genome for under $1,000—compared with the $2.7B cost of the original project—and in less than a week. Estimates suggest this will soon be even quicker and cheaper.
The human genome project spawned myriad research studies into human genomics including a significant number of genome wide association studies (GWAS) that scan participant samples looking for genetic variants that may cause different diseases. These now form the backbone of the polygenic risk scores (PRS) that are starting to be rolled out in many clinics across the U.S. to test for predisposition to cancer and other conditions.
However, the populations these tests are derived from are largely of European ancestry, bringing their accuracy for diverse populations into question. In an era where health disparities for minority and underrepresented populations in the U.S. cost huge amounts annually—both financially and in terms of illness—this is yet another example the overall inequality of the health system.

Evaluating the problem
While human genomes are 99.9% similar to each other regardless of race or ethnicity, significant genetic variation—mostly in the form of single nucleotide polymorphisms (SNPs)—occurs in and between different populations.
Knowledge of the type and frequency of these genetic variants can make a big difference to how certain diseases are diagnosed and treated. It can also help healthcare providers advise their patients about risk and disease mitigation strategies.

Howard University
Nicole Thompson is a genetic counsellor based at Howard University in Washington, D.C. She told Clinical Omics that a lack of diversity in genomics can cause problems when advising patients.
“When I send out a specimen to the lab… for my white population, they say, ‘This is a mutation in this particular gene, this person has this specific risk for cancer.’ But then when it comes to people of color, they say ‘Well, this is actually a variant of uncertain significance. We’ve never seen this before, it’s never been reported in the literature, we don’t know if this person has an increased risk for cancer, or if this is something they naturally carry.’”
The GWAS studies most PRS scores are based on are largely comprised of people of European ancestry. In 2020, Melinda Mills and Charles Rahal, researchers based at the University of Oxford, set up the GWAS Diversity Monitor to try to shine a light on how poor the diversity of these studies actually is.
The tool accumulates data from all published GWAS studies. As of July 2021, the vast majority (88.6%) of all GWAS participants were of European origin. Of the rest, around 7% of the participants are Asian, 0.35% African, 0.87% African-American or Afro Caribbean, 0.9% Hispanic or Latin American, and 2.21% listed as ‘other’ or ‘mixed’ ancestry.
Considering that 18.5% of the U.S. population identified as Hispanic or Latino, 13.4% as Black or African American and 5.9% as Asian in 2019 census estimates, these GWAS numbers are certainly not representative of the wider population.
“If you only study Europeans, you’re missing a lot of genetic diversity that only exists in other ancestries. And some of those variants, even though they may be very rare in Europe, may be reasonably common in other ancestries and actually have very big effects in terms of disease risk, and diagnosis,” Inês Barroso, a professor specializing in human genetics and diabetes at the University of Exeter in the U.K., told Clinical Omics.
Diabetes is a condition that varies considerably in risk and prevalence in different populations. Barroso cited a diabetes-associated variant she discovered a few years ago with colleagues that is very common in people of African ancestry and has a minor allele frequency of 11% in African Americans.
“It has a big effect size on a measurement of glucose called glycated hemoglobin, which is used to diagnose diabetes. We were able to estimate that if you didn’t know about this particular variant, and you were using this assay to try and diagnose diabetes, you might actually miss up to 650,000 African Americans in the U.S. that would have diabetes,” she explained.
Although there are similarities between different populations, it’s important to understand that you can only achieve highly accurate results for predicting risk or for making diagnoses if you have previously sampled the population you are testing.

University of Campinas, Brazil
Brazil is a good example of this, as it has a highly diverse and admixed population. Iscia Lopes-Cendes, a professor of human genetics based at the University of Campinas, knows this only too well as she and her team have researched this topic for a number of years.
“There are already publications showing that the commercial panels for diagnosis of breast cancer don’t work as well in the Brazilian population,” she explained. “That includes the regular panel that is used in Europe and the United States, as well as a Latino panel that was developed in the United States. It does not work for Brazilians, because it was developed based on the mutations that were common in the Latino population in the United States, which mainly derive from Central America.”
The reason for the continued low representation of non-white European populations is likely multifactorial. There is a reliance on existing cohorts. Early study and biobank cohorts that are largely made up of people of European ancestry—such as the UK Biobank—tend to be reused multiple times. Other factors have included a preference for populations that have uniform ancestry, which makes analysis easier, lack of funding for efforts to enroll more under-represented groups in genomic studies, and some early (now disproved) ideas that genetic variation such as SNPs would be the same across different populations, according to a 2019 paper published in Nature.
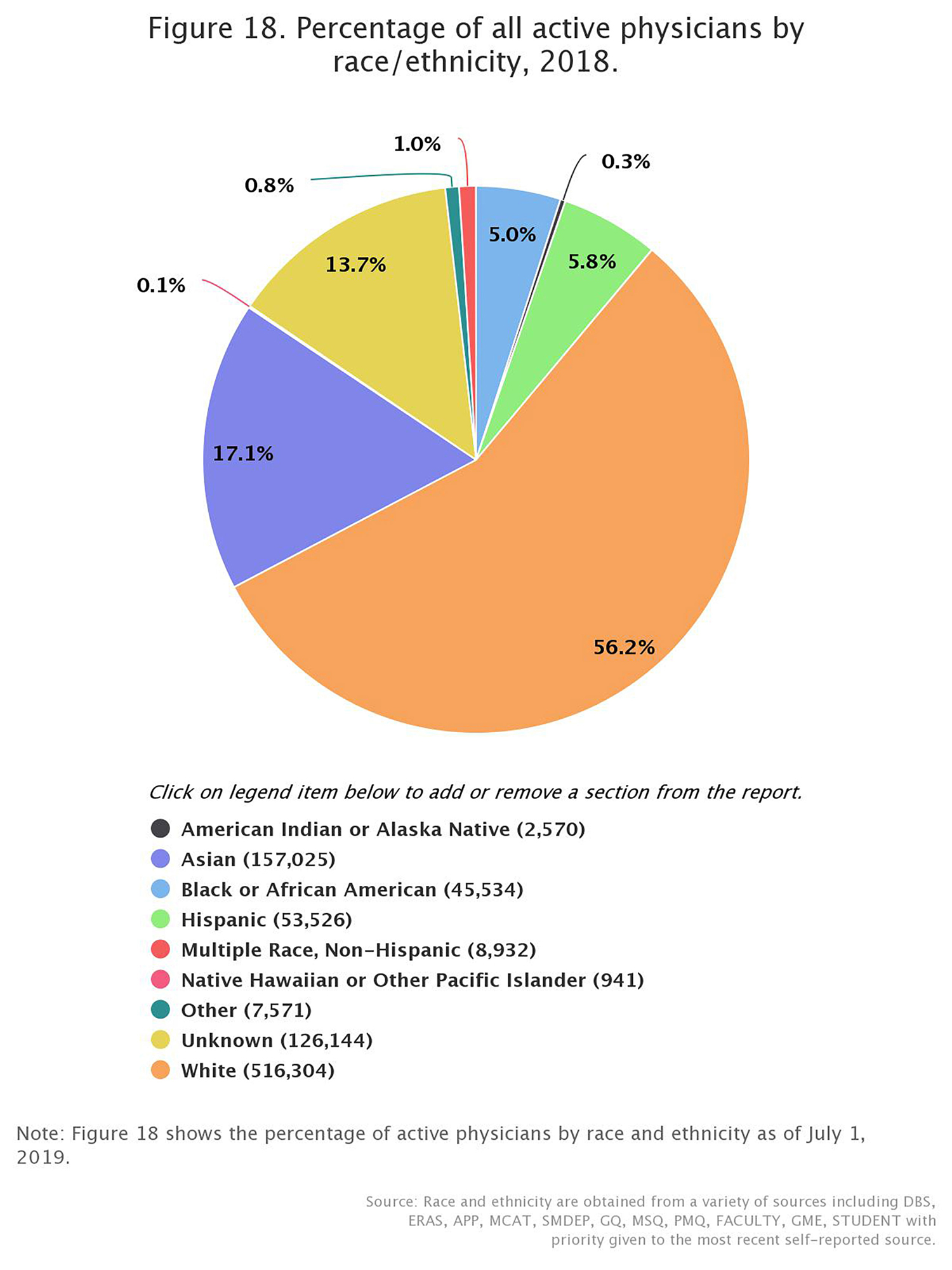 There are known healthcare disparities between those of white European ancestry and those identifying as Hispanic, Asian or Black in the U.S., so poor diversity in genomic studies that are then used to create clinical tests further adds to this issue.
There are known healthcare disparities between those of white European ancestry and those identifying as Hispanic, Asian or Black in the U.S., so poor diversity in genomic studies that are then used to create clinical tests further adds to this issue.
“The lack of diversity in healthcare in general is a huge problem that we’re seeing the ramifications of right now. There’s also a lack of diversity of physicians, I think in the U.S. maybe 5% of our doctors are black. And then for genetic counselors, it’s around 2% or less,” said Thompson.
Ongoing solutions
One of the first resources set up to try and better map diversity across different populations was the HapMap Project, established in 2003. The first ‘map’ release from the project in 2007 recorded more than 3 million SNPs in almost 300 individuals from Japan, China, the United States and Nigeria, with the project eventually being expanded to include 11 different populations in total.
It was followed by the 1000 Genomes Project in 2008, which aimed to create a more extensive collection of human genetic variation by sequencing 1,000 genomes sampled from a range of population groups. More than 2,500 genomes were completed by the time it finished in 2015, across 26 population groups on five continents, and the database is still widely used today.
The 1000 Genomes Project highlighted the importance of rarer, population-specific variants on human health and demonstrated the importance of including more diverse, non-European populations in genetic studies.
In the last decade, several projects in different countries launched to try to rectify these disparities. The Human Heredity and Health in Africa Initiative, also known as H3Africa, is a continent-wide consortium of human geneticists and other researchers, supported by the U.S. National Institutes of Health (NIH) and the U.K.’s Wellcome Trust, which was set up in 2011.
Last year, members of H3Africa published an important study in Nature that involved whole-genome sequencing of 426 individuals from 50 different population groups across Africa. This study revealed 3 million new genetic variants and striking differences between African population groups and Western European groups.

University of the Witwatersrand, South Africa
“Our recent study highlights how much we can still learn by even adding a relatively small number of genomes from understudied populations,” Zané Lombard, one of the authors of the 2020 paper who is a researcher at the University of the Witwatersrand, Johannesburg, told Clinical Omics.
“We also show that we are not yet reaching a plateau in new discoveries, and therefore can learn much more by increasing the number of African genomes available in the global resource.”
A new genome project for Africa—the Three Million African Genomes (3MAG) project—was proposed last year as a next step to learn more about the broad genetic diversity across the continent, but how easy it will be to set up such an ambitious project is uncertain.
“Funding for such a large-scale agenda might be challenging,” said Lombard. “There is a definitive need for political will and support from local governments to ensure the success of such an initiative. It is important that the scientists involved make a clear case for the potential health, infrastructural and intellectual benefits to ensure buy-in from local Health and Science Ministries. Although there is a good foundation of sequencing technology on the continent, I would imagine that a major investment in further high-throughput facilities on the continent would be necessary.”
Other projects have also been set up to provide better representation of different populations such as the GenomeAsia 100K project, which aims to sequence 100,000 Asian genomes. A pilot of the project has already been carried out and was published in 2019. Overall, 1739 individuals from 219 population groups across Asia were included. In Brazil, the Brazilian Initiative on Precision Medicine (BIPMed) is working to improve human genomic databases and run studies in the region. Researchers are leading the individual projects, but there is a centralized government coordination.
In the U.S., which has a highly admixed population, there are also efforts to improve recruitment of individuals from non-white backgrounds such as the NIH-funded All of Us Research Program, which began in 2018 and is aiming to sequence 1 million genomes over the next 10 years. So far, almost 50% of participants identify as non-white or of mixed ancestry, a significantly higher proportion than that of many earlier projects and studies.
There is a significant dilemma for human genetics researchers as nobody wants to waste the large amount of time and effort that has gone into creating databases such as the UK Biobank, which largely comprises individuals of European ancestry, as well as many other similar resources.

University of Colorado Denver
“One of the issues that we saw was we have these really large public databases like gnomAD, which are incredibly useful… The problem is that this data doesn’t match all of our ancestral populations very well,” Audrey Hendricks, a researcher at the University of Colorado Denver, told Clinical Omics.
“This is especially true for understudied populations, such as people with African ancestry, but also admixed populations. People still want to use the databases, but they’re not a good match. So, they can end up with biased results.”
Several statistical and computer-based methods to help improve the accuracy of health-related genetic risk predictions and to allow for population stratification in non-white populations have been developed to try and combat this problem.
For example, Hendricks and team recently developed a method called Summix to help collect more accurate ancestry-adjusted allele frequencies from genomic data. “If we have a sample of people, and we have their allele frequencies, we can model that sample as a mixture of reference ancestries,” she explained.
“We put in mixture proportions and we generate a new estimated allele frequency. And so, we can put in a mixture proportion for African and say, ‘Well, what if we had 100% African ancestry and 0%, European? What if we have 90%, African and 10%, European’, and so on, and then we compare that to what we observed. And when we do a good job of identifying those mixture proportions, we’re going to have a very small difference between what we observe and what we’re generating with our reference data.”

the Broad Institute
Another example is the Tractor software developed by Elizabeth Atkinson, a researcher at the Broad Institute, and her colleagues.
“Admixed individuals, by which we mean here people with recent ancestry from multiple continents, are often left out of large-scale genomics studies due to their complex genetic makeup,” she explained.
“We effectively ‘paint’ everyone’s genome using a reference panel so we can tell the ancestry backbone on which each allele is falling at each spot in the genome in each person. We use this local ancestry information in a novel GWAS model to get ancestry-specific association results. In other words, we estimate the effect of having a risk variant in each ancestry background, rather than just having a sort of aggregate measure.”
Remaining challenges
Although there are some excellent projects that have been set up to recruit more underserved populations into genomic studies, challenges remain. Software and tools such as Tractor and Summix are useful, but can only go so far and do not produce data of the same quality as studies that start with a diverse population.
Due to past research misconduct and discrimination against minority populations in medical studies, also cases such as that of Henrietta Lacks (the African-American donor of the HeLa cell line) whose cells were taken without permission and whose family were not compensated, people from black or minority ethnic populations are understandably skeptical about participating in genetic or genomic sequencing studies.
Thompson thinks the answer to persuading more people from minority backgrounds to join genetic studies is to get more people of color involved from the start. “Working at Howard University Hospital, the majority of our population is black or Hispanic… I’ve learned that cultural competency and shared language is extremely powerful. When you’re talking to someone that’s from the same culture as you that speaks the same language as you it’s just a natural flow that I think makes the patients feel a lot more comfortable disclosing personal information,” she explained.
“We did a study here, almost 10 years ago now, where we recruited people of color into cancer genetics research studies, and we had a 99% success rate. Most of that was attributed to having black genetic counsellors and having black doctors involved heavily in the recruitment process.”
Thompson also suggests that giving people some kind of incentive to join studies, whether financial or otherwise, could help with recruitment of minority groups.
“I think if we took the approach of offering something to the patient, for them giving something to science, I think it will make people feel a little bit better about their participation. Not necessarily to say that their genetics is for sale, but to say ‘you now have ownership in this’ or ‘we’re going to offer you royalties for the things that we develop because of your contribution.’”
Another challenge is funding large scale genomics projects, as many of the overlooked populations that are missing from genomic databases originate in countries that have limited financial resources. This means that scientific expertise, training and capacity in these countries can be lower for this reason.
“If we’re developing methods and infrastructures that you need a lot of money and a huge computer cluster to access the data, or to use the methods it’s just not equitable,” says Hendricks.
She says that the development of improved cloud computing resources, such as the NHLBI BioData Catalyst and the AnVIL project, for research is helping to improve this issue. Expensive and high-powered computers are typically needed for analysis of genomics data and so taking things onto the cloud helps make international collaborations easier.
Another important point that is becoming more important as studies increasingly become multi-omic, is that diversity is not just important for GWAS studies and genome sequencing.

University of Exeter, U.K.
“If I have a variant that I think is non coding, but affects regulation, or expression levels of particular gene, if that variant is only seen in African Americans, or Africans and I don’t have an expression data set to match that to I can never find the effect of that variant on the expression levels,” emphasized Barroso. Although people are starting to produce these kinds of data sets, they are currently few and far between.
When aiming to improve diversity, it is also important not to create unintentional or unexpected biases, Lopes-Cendes cautions. “H3Africa is doing a wonderful job, but there are still limitations. For instance, the Portuguese speaking countries are not involved,” she said.
“Even in Europe, there are some underrepresented populations, especially when you look at public databases. They include more European populations, but if you look at the Southern Europeans, they’re not as represented.”
With high levels of global immigration and emigration around the world, and ever improving ‘omics technology it’s vitally important that we ensure that study cohorts and databases are as diverse as possible and that medical genetic tests such as PRS have been developed on the population that they are being used on.
“Especially in countries where they are starting to think about precision medicine approaches, you want to make sure in that country, you’re not leaving behind populations that are already at a disadvantage. When you’re driving a precision medicine approach, you absolutely want to make sure that you’re including, and increasing their diversity representation from your own country,” said Barroso.
“We always need more, I think that’s the message,” added Lopes-Cendes. “It’s never enough…we really have to capture as much as possible of human diversity.”
Projects Contributing to Improved Genomic Diversity
All of Us–U.S. based project started in 2018. Aims to sequence 1 million diverse genomes over the next decade.
Trans-Omics for Precision Medicine (TOPMed)—U.S. based project launched in 2014. The whole-genome sequencing part of the TOPMed program, has sequenced over 90,000 genomes, including 47,020 participants of African ancestry, and aims to sequence more than 120,000 in total.
Million Veteran Program—Launched in 2011, this biobank has already enrolled more than 830,000 Veterans in the U.S. including many from diverse backgrounds.
Million African Genomes project—Ambitious African project proposed in 2020. Plans to sequence 3 million African genomes across the continent
GenomeAsia 100K—Started in Singapore in 2016, this project aims to sequence 100,000 genomes from across Asia.
Brazilian Initiative on Precision Medicine (BIPMed)—Launched in 2015, this is Latin America’s first public human genomic database.
BioBank Japan—Began in 2003, the project recruited 260,000 patients representing 440,000 cases of 51 primarily multifactorial (common) diseases.
The Qatar Genome Programme—This pilot phase of this project started in 2015 and aims to sequence the genomes of 350,000 inhabitants of Qatar.
Genome India Project—Started in 2020, this project aims to sequence 10,000 genomes across the country.
Human Heredity and Health in Africa (H3Africa)—A consortium begun in 2011 that links up researchers in human genetics around the country and facilitates genomic studies.
Organizations, Websites, and Online Tools
The Global Alliance for Genomics and Health (GA4GH)—The GA4GH is an international, nonprofit alliance formed in 2013 to accelerate the potential of research and medicine to advance human health.
GWAS Diversity Monitor—An online tool set up in 2020 to highlight diversity in genome wide association studies.
International Common Disease Alliance (ICDA)—The ICDA is a scientific forum comprising international stakeholders from industry and academia to develop ideas and accelerate progress in common disease genetics discovery and translation.
BioData Catalyst—The NHLBI BioData Catalyst is a cloud-based platform providing tools, applications, and secure workflows for medical and life science researchers.
AnVIL Project Cloud-Based Computing—The AnVIL platform is NHGRI supported and runs on the Google Cloud Platform (GCP). It enables researchers to analyze open and controlled access genomic datasets with popular analysis tools in a secure cloud computing environment.






